
Vårt delingshjørne


Lars Espen
Nordhus
4. november 2020
Dette er del tre i en artikkelserie på tre deler om ytelse. Del én finner du her, og her er del to.
Selv om dette er en blogg om ytelse, er det verdt å nevne at ikke alle problemer bør løses med ytelsesforbedringer i kode. Alternativer kan for eksempel være å last-balansere, skalere ut, skalere opp eller endre kravene til løsningen.
Skalere opp er begrepet man bruker om det å skru på bedre maskinvare på en løsning, for å få den til å gå raskere. Ta eksempel at du har en bærbar PC som går sakte. Da er det ofte smartere å kjøpe en bedre bærbar PC, enn å kjøpe to dårlige som man jobber på i parallell.
Det motsatte av dette er å skalere ut og det kan da sammenlignes med å delegere arbeid i et firma, slik at ikke alle venter på at en person skal jobbe. En ekstrem versjon av dette er peer-to-peer, der man fordeler problemstørrelsen så godt som mulig, slik at ingen til slutt ender opp med å være serveren.
En last-balanserer er som man kan forstå av navnet, en teknologi som fordeler last så jevnt som mulig utover flere servere (eller andre enheter som kan ta imot last). Som regel setter man opp en last-balanserer ut mot brukerne da man ikke har helt kontroll på når brukere bestemmer seg for å bruke systemet og derfor må bygge systemet for å tåle maks last i kortere perioder. Siden dette er en mye brukt tjeneste, har man begynt å legge inn mer avanserte valg og funksjoner her. Du kan velge å balansere på bakgrunn av IP eller ressurs/url, du kan sette opp «Affinity», «Persistence» eller «sticky session» som hjelper deg å sende brukere til samme instans bak last-balansereren i en gitt periode og mye mer.
MEN AV OG TIL KOMMER MAN INN PÅ PROBLEMER DER DET IKKE ER NOK Å SKALERE OPP OG DET IKKE FUNGERER Å SKALERE UT.
Men pass på enkelte last-balanserere og andre teknologier kan hjelpe deg med å cache deler av din løsning. Dette kan være smart for å øke ytelsen drastisk på enkelte deler av applikasjonen din, men kan også føre til at udatert informasjon, eller informasjon man ikke skulle hatt tilgang til, blir levert ut dersom du setter dette opp feil. «Kenneth-saken» hos Altinn var en slik feil som fikk mye oppmerksomhet. Se mer her: https://www.cw.no/artikkel/offentlig-sektor/slik-oppsto-altinn-feilen. Da de endelig fikk fikset feilen så de at: «Fjerning av "cache"-funksjonaliteten kan nå imidlertid føre til at systemet blir tregere ved høy belastning.»
Punktene over er ting alle utviklere bør ha et forhold til og som ofte kan løse problemet relativt billig. Men av og til kommer man inn på problemer der det ikke er nok å skalere opp og det ikke fungerer å skalere ut. Hva skjer når den sekvensielle delen av koden din som du ikke får til å parallellisere blir for stor?
Begrenses av sekvensiell del
Om det er flere kall fra flere brukere, eller om du velger å parallellisere en del av din algoritme, vil den teoretiske «max speedup total» være avhengig av størrelsen på den sekvensielle delen av koden din. Dette kan sammenlignes med en prosjektleder som styrer teammedlemmer. All info kommer fra og til teamet via prosjektlederen. Prosjektlederen kan bli en flaskehals og må bruke tid på å være i møter for å få info som skal delegeres til teammedlemmene. Siden prosjektlederen skal ha oversikt blir han den sekvensielle begrensingen, og det hjelper derfor ikke å legge på flere medlemmer i teamet da oppgavene som kan delegeres ikke kommer inn raskere. Logisk nok, som du ser på figuren under (Amdahls-law), vil det ha lite virkning å parallellisere noe som hovedsakelig begrenses av en sekvensiell del.
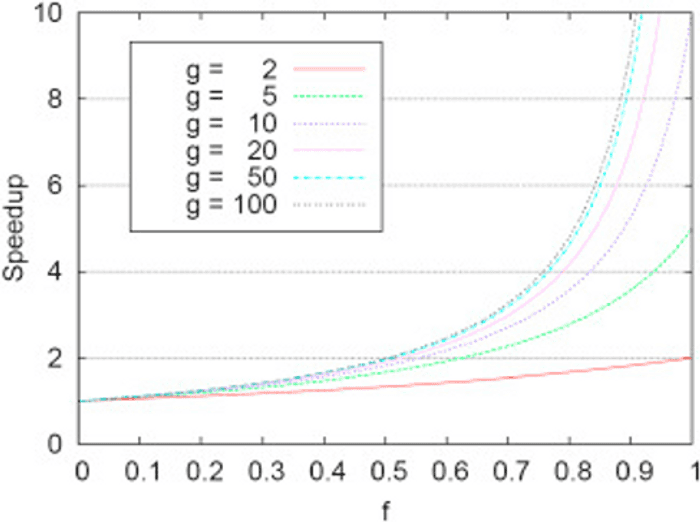
Figur 1: Resultatet av Amdahls-law.
G=Beste parallellisering for algoritmen.
F=Prosent av algoritmen som kan parallelliseres.
Speedup=Hvor mange ganger algoritmen kan være ferdig på samme tid.
https://www.sciencedirect.com/topics/computer-science/amdahls-law.
Men hva skal man gjøre da?
Som du ser av figuren så vil en algoritme som har 50% av kjøretiden sin i en sekvensiell del aldri klare å ha mer enn dobbelt så rask kjøretid. Det vil si, du blir aldri kvitt den serielle delen uavhengig av hvor mye du parallelliserer. Fargen på grafen sier noe om hvor rask den tregeste delen av programmet teoretisk sett kan gå, gitt at den parallelliseres optimalt.
DERSOM DU IKKE KAN REDUSERE DEN SEKVENSIELLE DELEN OG DU IKKE KAN GJØRE FLERE ENDRINGER TIL ALGORITMEN, ER ENESTE LØSNING Å FLYTTE TIL BEDRE MASKINVARE.
Når den serielle delen blir for stor er det ofte en bedre løsning å velge en mer naiv algoritme, som er lettere å parallellisere og derfor gir en mindre sekvensiell del dersom du har mer CPU tilgjengelig. Et eksempel på dette er MapReduce, som revolusjonerte markedet innen Big Data, ved å gjøre ting enklere og mer naivt, men samtidig skalerte utrolig bra. Kort forklart, så brøt man jobber ned i små sammenligninger som kunne gjøres i massiv skala (https://research.google.com/archive/mapreduce-osdi04.pdf). På denne måten klarte man å bruke billigere og dårligere maskinvare i haugetall for å gjøre aggregering og søk i data som før hadde vært umulig.
Et annet verktøy er å endre måten man lagrer dataen i minne slik at kjøretiden på den sekvensielle delen av koden blir kortere. Standard for mange er at man f.eks. bruker lister og søk i lister. Dersom søk eller oppslag er hoveddelen til din sekvensielle del bør du kanskje sjekke ut «Dictionaries» eller «HashMaps». Disse er spesialisert på å gi deg rask uthenting av data så lenge du vet nøkkelen.
Dersom du ikke kan redusere den sekvensielle delen og du ikke kan gjøre flere endringer til algoritmen, er eneste løsning å flytte til bedre maskinvare. Dette har tidligere vært veldig vanskelig, siden man da må gjøre større investeringer. Men med skyløsninger er det blitt mulig å utføre tester og skalere i løpet av minutter. Det kan virke fristende å gjøre en større omskriving for å øke ytelsen minimalt, men pass på å sammenligne dette med kosten av å oppgradere til bedre maskinvare eller de andre tiltakene nevnt tidligere i bloggposten. Og siden man vet at maskinvareytelse blir billigere over tid, har man en ekstra grunn til å bruke dette grepet.
Eksempel:
Et eksempel som jeg synes illustrerer dette godt, er hvordan Ruter-appen for buss i Oslo gikk ned tidligere, dersom det var dårlig vær. Dette var en effekt av antallet brukere som kontinuerlig prøvde å oppdatere appen, med hvor lenge det var igjen til deres buss kom. Dette førte til at brukerne i praksis DDOS-et serven og systemet stoppet opp. Som et resultat av dette, innførte Ruter «cache» ved å bare oppdatere estimatet på bussen etter en viss tid, og derfor kunne sende ut den lagrede verdien uten utregninger frem til et nytt estimat var blitt regnet ut. På denne måten kan man sende samme info til mange brukere i parallell og slik skalere nesten uendelig og dynamisk hvis ønskelig.
Et kombinert problem
Nå har vi gått gjennom mye teori. Det er da tid for et større konkret eksempel der vi fikk bruk for mye av det som vi nå har gjennomgått, som førte til at vi gikk fra en kjøretid på over 48 timer til 9 sekunder.
Hos en kunde, som kunne vært hvem som helst, skulle det lages en løsning som fant ut hvilke jobber som hadde feilet uten feilmelding. Vi hadde en liste med 500 000 meldings-IDer som hadde blitt sendt til systemet, og et sett med lager som holdt på alle meldinger som hadde blitt prosessert ferdig. De meldingene som var feil, skulle bygges opp på nytt og sendes gjennom systemet for ny prosessering. Problemet var relativt enkelt, og alle var positive.
En av utviklerne kastet seg på oppgaven og var snarlig klar med en konsoll-app som skulle løse problemet. Men ting så ut til å henge! Koden ble saumfart for bugs, men intet ble funnet. Utvikleren prøvde å la applikasjonen kjøre i bakgrunnen 2 timer før han måtte pakke sammen for dagen, men hadde fortsatt håp om at jobben var nær målet. Dagen etter kjørte han i gang en kjøring som resulterte i 8 timer før han igjen måtte pakke sammen pc-en og programmet måtte stoppes.
Det begynte å bli dårligere stemning og vi samlet oss for idemyldring. Vi startet med å kjøre opp koden i debug og la inn en timer som printet kjøretiden pr 1000-ende rad et sett med steder og lot den kjøre litt. Etter å ha hentet ut litt tall regnet vi ut at dette kom til å ta over 48 timer å kjøre dersom vi ikke gjorde tiltak. Siden dette er noe som ikke skulle kjøre så ofte, vurderte vi å bare sette opp en server som kunne kjøre dette uavbrutt. Men det var litt vel lenge for de som lette etter feil å måtte vente 48 timer før de fant igjen meldingene sine.
Som resultat av dette satt vi oss heller sammen og parprogrammerte en ny løsning med fokus på ytelse. Vi la inn timere og breakpoint som sjekket hvor mye tid som ble brukt i forskjellige deler av koden. På denne måten kunne vi finne hvilke deler av koden som var viktig å bruke tiden vår på og hvilke deler som fungerte fint som den var. Delen som ga problemer, viste seg å være den delen der vi hadde noen hundre tusen rader med data som skulle filtreres på bakgrunn av om de eksisterte i en rekke andre datalager. Utfordringen oppsto som resultat av at databasen var en «table store» som var optimalisert for raskest lesing og skriving gitt at man hadde datoen for kjøringen. På denne måten var det lett å finne din data når du visste hvilken kjøring du ville se på. Men utrolig vanskelig for oss når vi skulle finne ut om et element hadde vært del i en kjøring på tvers av alle kjøringer.
Måten vi først løste dette på, var å gå sekvensielt gjennom hvert element i de mange hundre tusen elementene og søke gjennom de mange tusen elementene i en kjøring en kjøring av gangen. Dette førte til veldig mange oppslag, nærmere 1,500,000,000,000 sammenligninger, og nesten all tid ble brukt på venting på IO og nesten ikke noe CPU og minnebruk.
DET ER LETT Å INTRODUSERE FEIL, OG MAN BØR PRØVE Å IKKE PARALLELLISERE STØRRE DELER ENN MAN KLARER Å HA OVERSIKT OVER PÅ EN GANG.
Det ble fort klart at vi både måtte parallellisere og cache data på noe vis, men før vi kunne gjøre det trengte vi å forstå koden vi skal parallellisere bedre. Det er lett å introdusere feil, og man bør prøve å ikke parallellisere større deler enn man klarer å ha oversikt over på en gang. Det å tenke ut og finne alle mulige dead-locks og race-conditions for ikke å snakke om å fikse dem, kan være utrolig vanskelig og på kanten til umulig når kodebasen blir stor nok. Vi satt oss derfor ned sammen og skisserte ut flyten og alle punkter der man lagret, mellomlagret, leste eller endret verdier som kunne benyttes på tvers av tråder.
Deretter utforsket vi dataen vi skulle jobbe med for å vite hvilke ID-er som var garantert unike, og hvordan vi kunne lagre data best mulig for vår algoritme. Da dette var gjort, startet vi med å lage et mindre uttrekk av dataen som var raskere å jobbe med, men som fortsatt ga litt kjøretid som kunne forbedres. Ved å lese inn ID-er fra alle lager og kombinere dem til objekter med sett av ID-er og å legge disse objektene i en liste, klarte vi å lage vår egen miniversjon av dataen som lå spredt i alle databasene. Deretter laget vi en ny liste med alle id-ene vi skulle søke etter og kjørte Linq.Join (C# listemetode) på de to listene. Dette fungerte utrolig bra, men uthentingen av dataen tok fortsatt flere timer. Dette var en stor forbedring, men vi hadde kommet for langt til å gi oss nå. Som vi så tidlig, kom dette til å trenge parallellisering. Vi satt opp en tråd for hver dato man hadde kjørt en kjøring og fikk dermed en god segmentering av dataen. Dette gjorde at kjøretiden gikk fra timer til ca. 10 minutter. Ved å skrive dette om til å gjøre en sammenligning ved uthenting og skrive denne dataen til et nytt lager for senere bruk, kunne vi nå gjøre nye sammenligninger og uttrekk på ca. 9 sekunder gitt at man gjør det ca. en gang i måneden.
En bieffekt av at vi klarte å få kjøretiden så drastisk ned, var at brukerne nå hadde lyst til å få dette som en self-service tjeneste. Koden ble dermed sydd inn i en av våre andre tjenester med gode tilbakemeldinger.
Oppsummering
Fra 48 timer til 10 minutter ved å parallellisere uttrekk av azure table store og matche dette med ett og ett segment av data som skulle matches og da ved å bruke Linq.Join fremfor forloops med if. Dette i kombinasjon med lagring av aggregerte resultater i cache ved hver kjøring slik at man ikke trengte å lese historisk data gjorde at vi kom ned til 9 sekunder.
Prøv å minimer tid brukt i sekvensiell del ved å bytte til enklere eller mer naive algoritmer som er lettere å parallellisere. Bruk teknologi som eksisterer for å øke ytelsen uten å trenge å skrive kode.
Tips til arbeidet med optimalisering:
Kjenn koden du skal parallellisere godt!
Ikke parallelliser mer enn du klarer å holde i hode på et tidspunkt
Finn hvilke deler av koden som trenger optimaliseringer før du legger inn arbeid
Cach data det tar lang tid å hente ut eller aggregere
Bruk innebygget metoder fremfor å skrive eget dersom mulig
Parallelliser når du har cpu og minne ledig og trenger hastighet
Bruk testdata som gir litt kjøretid men ikke for mye
Nå har vi gått gjennom det jeg syntes er de viktigste delene av arbeidet med optimalisering i vanlige prosjekter, men dette er bare toppen av isfjellet. Dersom du har noen kommentarer, spørsmål eller trenger å snakke med noen om ytelse, sende epost til Hei@alv.no eller skrive inn i kommentarfeltet under.



